
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 회고
- 데이터
- 데이터분석
- 네트워킹모임
- 비즈니스분석가
- SQLD
- 도서출판길벗
- HTML
- 취준
- it모임
- 주간회고
- 코딩테스트
- 회고글
- sql
- 커리어브랜딩
- 코테
- hackerrank
- airflow
- 오라클
- 데이터엔지니어링
- 유데미
- 생활코딩
- 테크커리어
- 윈도우함수
- 행사후원
- 데잇걸즈6기
- 데잇걸즈
- 취준생
- 해커랭크
- Oracle
Archives
- Today
- Total
Dream Lovers
SQL 윈도우 함수 (집계, 순위, 분포, 분석함수의 종류) 본문
Aggregate 집계 함수
- SUM() 합계
- AVG() 평균
- MAX() 최댓값
- MIN() 최솟값
- COUNT() 개수
SELECT
name,
region_id,
SUM(population) over(partition by region_id) as 합계,
MIN(population) over(partition by region_id) 최솟값,
MAX(population) over(partition by region_id) 최댓값,
COUNT(population) over(partition by region_id) 개수,
ROUND(AVG(population) over(partition by region_id),1) 평균
FROM eba_countries;
Ranking 순위 함수
Order by를 꼭 넣어야한다.
| 구분 | 설명 |
| ROW_NUMBER() | 동일 순위를 부여하지 않음 |
| RANK() | 동일 순위는 부여하되, 숫자 건너 뜀 |
| DENSE_RANK() | 동일 순위 부여, 순서 건너뛰기 없음 |
SELECT
name,
population,
ROW_NUMBER() OVER (ORDER BY population),
RANK() OVER(ORDER BY population),
DENSE_RANK() OVER(ORDER BY population)
FROM eba_countries;
Distribution 분포 함수
- ORDER BY절 필수 (oracle의 경우)
- PERCENT_RANK()
- 0~1 사이의 값
PERCENT_RANK() OVER( order by 절)
(rank -1) / (total number of rows in partition -1)
- CUME_DIST()
CUME_DIST() OVER( order by 절)
number of rows <= current rows value / total number of rows in partition
SELECT
name,
region_id,
population,
PERCENT_RANK() OVER (PARTITION BY region_id ORDER BY population),
CUME_DIST() OVER(PARTITION BY region_id ORDER BY population)
FROM eba_countries;
Analytical 분석 함수
- LEAD ()
윗 행으로 올리기
LAG(표현식, offset, [,default]) OVER (order by 절)
값이 null인 경우 default로 null로 표시됨.

- LAG()
아래 행으로 내리기
LAG(표현식, offset, [,default]) OVER (order by 절)
값이 null인 경우 default로 null로 표시
SELECT
name,
LAG(name) over(order by name) ,
LAG(name,2) over(order by name) ,
LAG(name,2,'blank') over(order by name)
FROM eba_countries;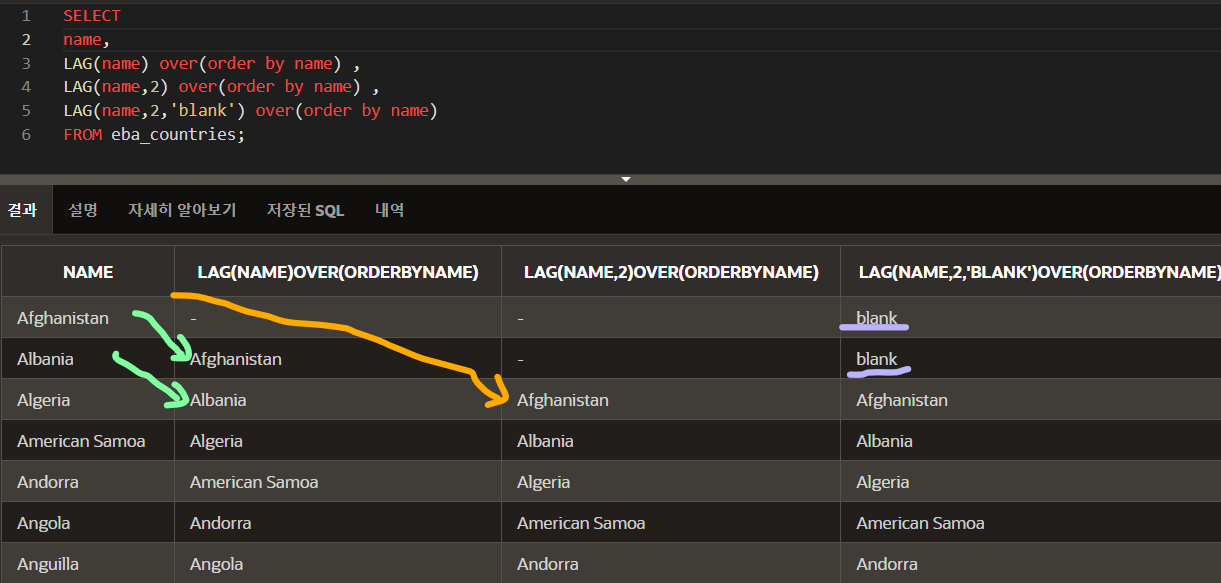
- NTILE()
Order by 절 필수
NTILE( number) OVER ( order by 절)
여기서 number는 묶을 그룹의 개수를 의미함
SELECT
name,
region_id,
population,
NTILE(3) OVER (PARTITION BY region_id ORDER BY population)
FROM eba_countries;위의 쿼리는 region_id별로 3개의 그룹을 만들라는 의미이다. 이 때 정렬은 population 오름차순으로 한다.



- NTH_VALUE()
NTH_VALUE(표현식, n) OVER()
여기서 n은 n번째 값을 의미한다. order by절은 필요 없음
SELECT
name,
region_id,
population,
NTH_VALUE(name, 2) OVER (PARTITION BY region_id)
FROM eba_countries;region_id별로 파티션을 나눴을 때, 2번째 행의 name을 가져오라는 뜻


SQL 실행 순서
FROM → JOIN → WHERE → GROUP BY → HAVING → WINDOW FUNCTION → SELECT → ORDER BY → LIMIT / FETCH / TOP
'SQL 쿼리 테스트 > Tips' 카테고리의 다른 글
| SQL 계층 쿼리 (START WITH, CONNECT BY PRIOR, ORDER SIBLINGS BY) (0) | 2023.09.10 |
|---|---|
| SQL 그룹함수 (ROLLUP, CUBE, GROUPING_ID, GROUPING SETS) (0) | 2023.09.07 |
| SQL 윈도우 함수 (구조, ROWS, RANGE의 차이) (0) | 2023.08.23 |
| SQL 데이터 피벗/언피벗 (pivot/unpivot ) (0) | 2023.07.29 |
| SQL 데이터 클렌징 (COALESCE, NVL, TRIM, PAD, GREATEST, LEAST) (0) | 2023.07.29 |
'SQL 쿼리 테스트/Tips' Related Articles
more



